Large Language Models are still flubbing the basics — including chess.
A fresh critique from AI thinker Gary Marcus highlights that LLMs don’t build or keep stable, interpretable, dynamic world models. This is a key reason why they mess up tasks that require tracking changing facts, like playing chess properly.
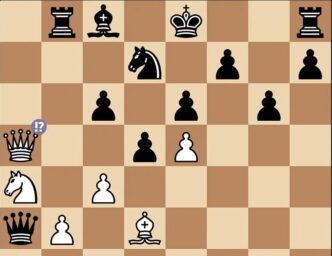
The issue started with examples like ChatGPT moving chess pieces illegally — such as a black player jumping a queen over a knight, a clear rules violation. Despite knowing and parroting chess rules perfectly on paper, these models fail to integrate that knowledge into real-time game states. 
Marcus pointed out:
ChatGPT, playing black, attempted to plays 7.. Queen takes Queen at a5, illegally jumping the knight, May 2025
He says no serious chess player would ever make that mistake — but LLMs do because they never create an actual, updatable internal model of the chessboard. Instead, they stitch together probable chess moves based on training data, without understanding the evolving positions.
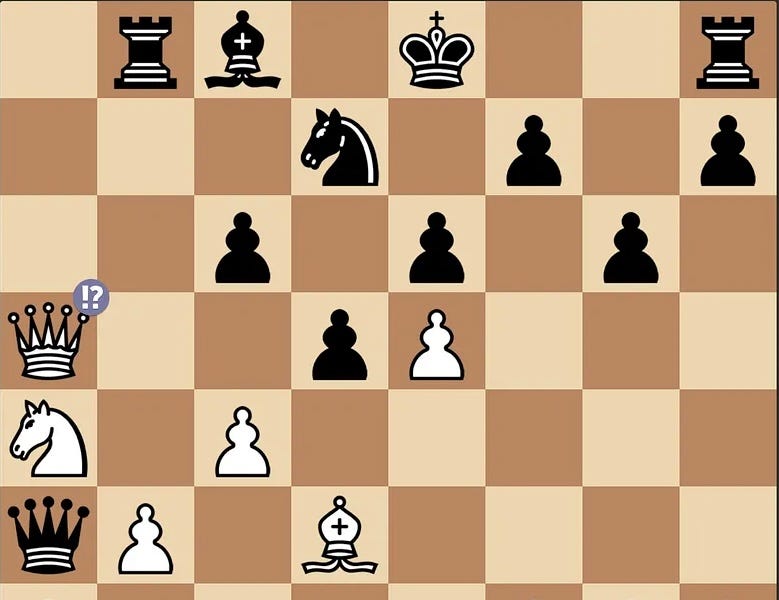
This problem extends beyond ChatGPT. AI researcher Mathieu Acher tested another LLM called o3, which made illegal moves like ignoring a pinned pawn. His summary:
I have (automatically) played with o3 or o4-mini in chess, and the two reasoning models are not able to [restrict themselves to ] …. legal moves …. The quality of the moves is very low as well. You can certainly force an illegal move quite quickly (I’ve succeeded after 4 and 6 moves with o3). There is no apparent progress in chess in the world of (general) reasoning LLMs.
An Atari 2600, released in 1977, even recently beat ChatGPT at chess — underscoring how far LLMs have to go on this front.
Marcus frames this failure as part of a bigger design flaw in LLMs: ignoring explicit world models entirely. Unlike classical AI programs, which build and update detailed internal representations of the world, LLMs rely solely on correlations in data.
He adds:
The sentences ChatGPT can create by pastiching together bits of language in its training set never translate into an integrated whole.
This gap explains why LLMs hallucinate factual errors, fail at math, struggle with video comprehension, and botch everyday reasoning tasks. It also has serious safety implications — such as AI systems ignoring their own safety guardrails or getting confused in complex scenarios.
For anyone expecting AI to handle problem-solving or real-world tasks autonomously — chess should be easy. Right now, LLMs can’t even hack that.
Gary Marcus continues to argue that robust, explicit cognitive models are essential for true AI progress. Without them, “everything that LLMs do is through mimicry, rather than abstracted cognition.”
The world’s most advanced LLMs might talk a good game. But when it comes to playing chess right — and understanding anything truly dynamic — they’re still stuck in the opening moves.