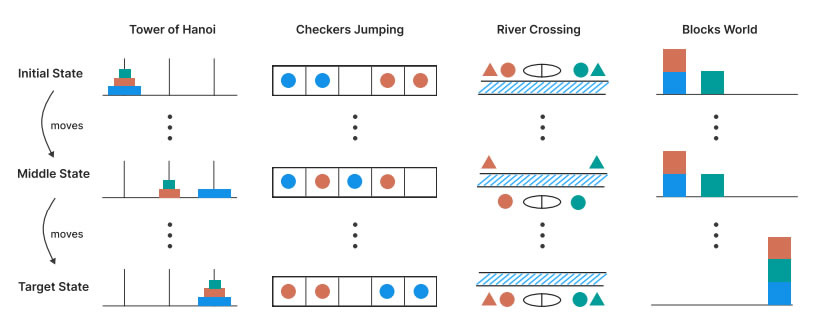
Apple researchers say top AI models still can’t really “think.” Their new paper, “The Illusion of Thinking,” slams current large reasoning models (LRMs) like OpenAI’s ChatGPT and Anthropic’s Claude for failing to reason consistently.
The team tested these models with puzzle games that pushed beyond normal math and coding benchmarks. They found models fall apart on harder problems, losing accuracy fast. Their “reasoning” is just mimicked patterns, not deep understanding.
“We found that LRMs have limitations in exact computation: they fail to use explicit algorithms and reason inconsistently across puzzles.”

Models even “overthink,” starting with correct answers but then getting lost in wrong reasoning. This clashes with claims that AGI is just a few years away.
“These insights challenge prevailing assumptions about LRM capabilities and suggest that current approaches may be encountering fundamental barriers to generalizable reasoning.”
OpenAI CEO Sam Altman recently said AGI is near. Anthropic’s Dario Amodei predicts it as soon as 2026 or 2027. But Apple’s test results suggest the race still has a long way to go.
See the full Apple paper here.