Amazon Bedrock just rolled out a new way to analyze huge piles of customer feedback—fast and with accuracy checks built-in. The key? Using multiple large language models (LLMs) as a jury to judge AI-generated summaries of text data.
The issue: manually sifting through thousands of free-text responses takes weeks. Traditional NLP methods can be messy and code-heavy. Enter LLMs, which speed up the process by generating thematic summaries. But relying on one AI to judge its own output invites bias and hallucinations.
The fix: deploy multiple LLMs on Amazon Bedrock—like Anthropic’s Claude 3 Sonnet, Amazon Nova Pro, and Meta’s Llama 3—to rate alignment between summaries and original feedback, acting as a panel of AI judges. This cross-validation cuts error risks and balances perspectives. 
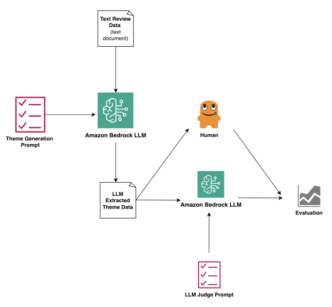
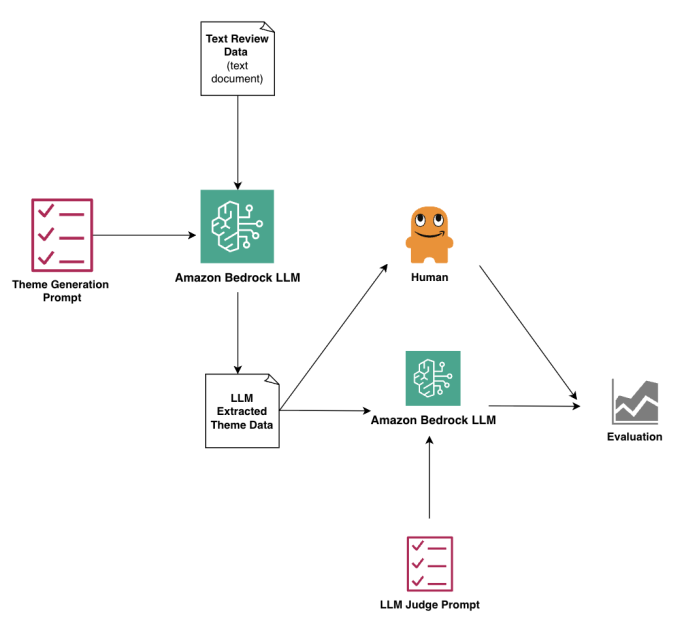
How it works:
- Upload raw feedback data to Amazon Bedrock.
- Generate thematic summaries using a pre-trained LLM.
- Have multiple LLMs review the summaries separately, scoring alignment on a 1 to 3 scale.
- Compare ratings using stats like Cohen’s kappa and Krippendorff’s alpha, with optional human judge scores as a benchmark.
This approach scales analysis while boosting reliability. Recent Amazon research found LLMs agree with each other up to 91%, beating human-to-model agreement at 79%. Still, human oversight remains critical for subtle context.
The best part? Bedrock’s unified API lets you test and compare multiple foundation models on the same data, picking the best fit for your needs.
Amazon’s walkthrough includes Jupyter notebooks and example code to get the jury system running in SageMaker Studio. Basic Python skills and an AWS account are all that’s needed.
This multi-LLM judge framework is now an effective weapon for businesses drowning in unstructured text, offering scalable, validated insights with less time and effort.
Dr. Sreyoshi Bhaduri from Amazon explained:
You can use Amazon Bedrock to compare the various frontier foundation models
such as Anthropic’s Claude 3 Sonnet, Amazon Nova Pro, and Meta’s Llama 3.
The unified Amazon Web Services (AWS) environment and standardized API calls
simplify deploying multiple models for thematic analysis and judging model outputs.
Amazon Bedrock also solves for operational needs through a unified security
and compliance controlled system and a consistent model deployment environment
across all models.
Dr. Natalie Perez added:
The strong performance of LLM-as-a-judge models opens opportunities to scale text data analyses at scale,
and Amazon Bedrock can help organizations interact with and use multiple models
to use an LLM-as-a-judge framework.
Check the full GitHub notebook to try it yourself.











